
Scaling Out
Map Reduce works for small inputs; now it’s time to take a bird’s-eye view of the system and look at the data flow for large inputs.
For simplicity, the examples so far have used files on the local filesystem.
However, to scale out, we need to store the data in a distributed filesystem (HDFS).
This allows Hadoop to move the MapReduce computation to each machine hosting a part of the data, using Hadoop’s resource management system, called YARN.
Data Flow
First, some terminology. A MapReduce job is a unit of work that the client wants to be performed:
it consists of the input data, the MapReduce program, and configuration information.
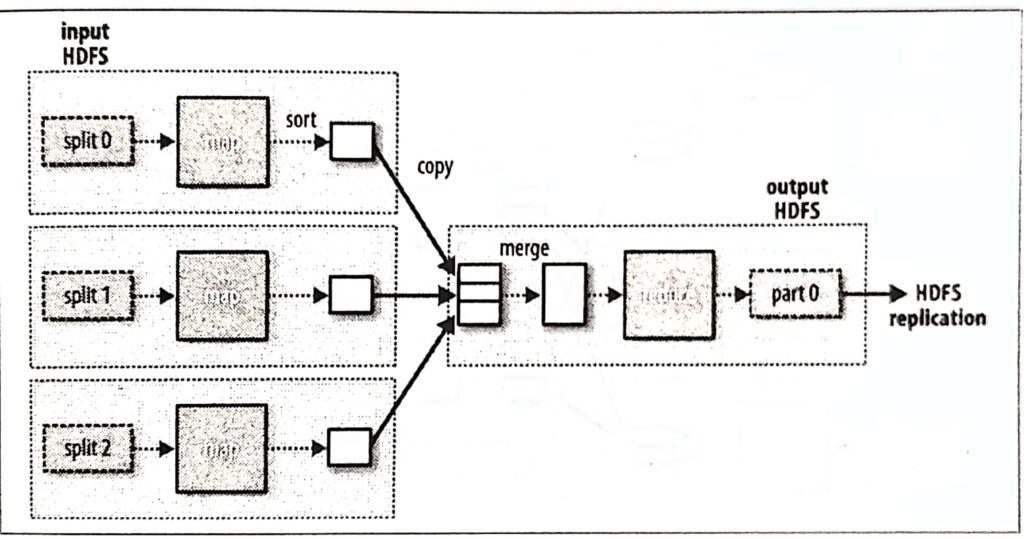
Hadoop runs the job by dividing it into tasks, of which there are two types:map tasks and reduce tasks.
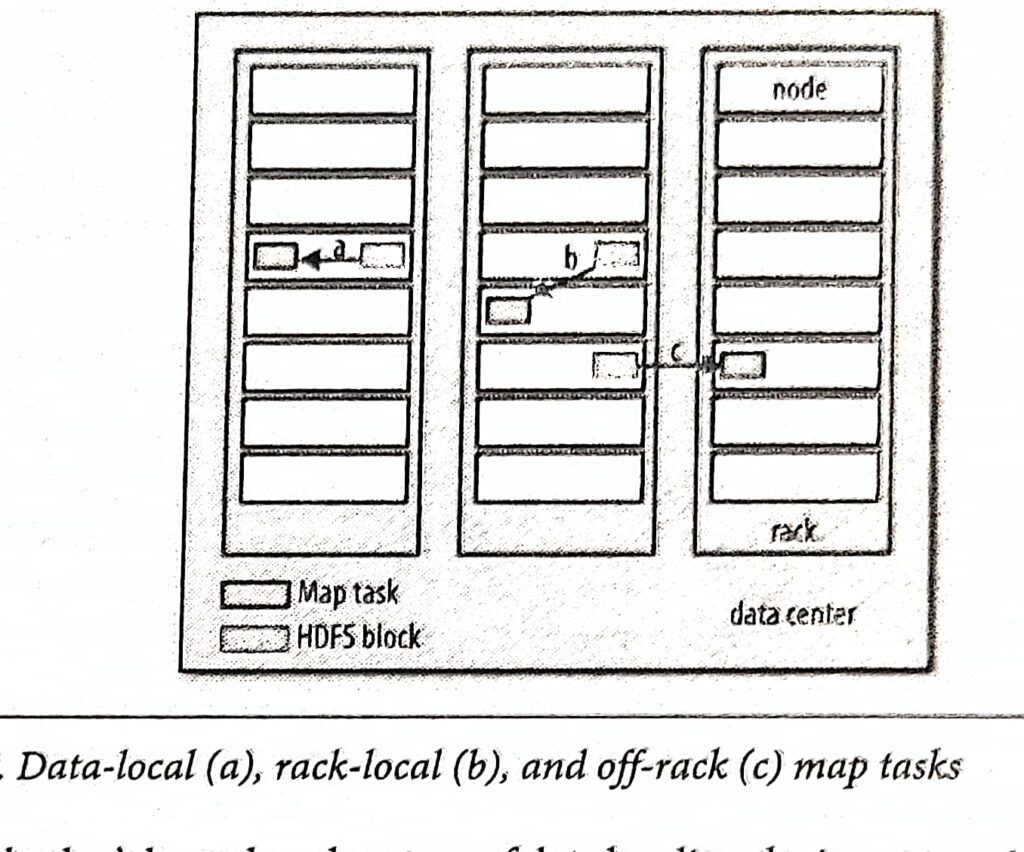
The tasks are scheduled using YARN and run on nodes in the cluster. If a task fails, it will be automatically rescheduled to run on a different node.
Hadoop divides the input to a MapReduce job into fixed-size pieces called input splits, or just splits.
Hadoop creates one map task for each split, which runs the user-defined map function for each record in the split.
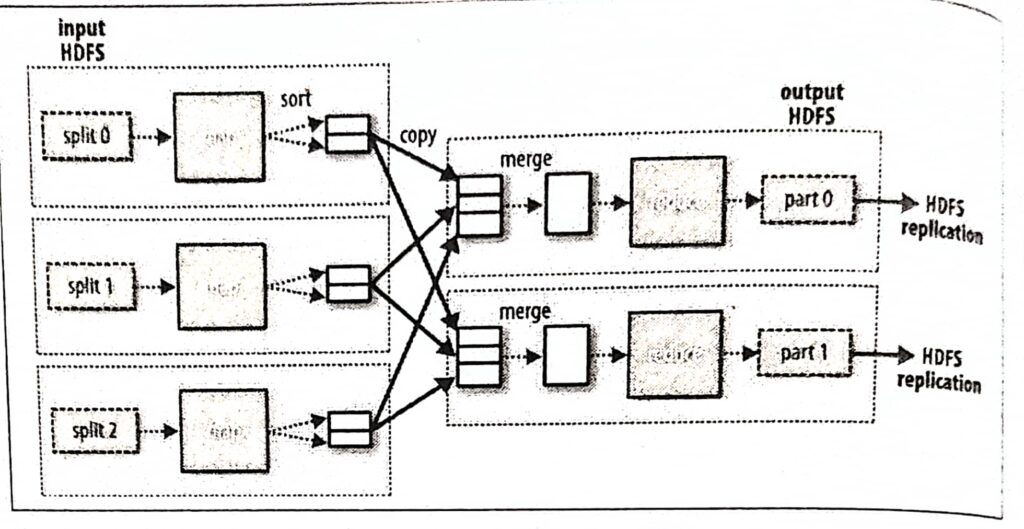
MapReduce data flow with multiple reduce tasks
Finally, it’s also possible to have zero reduce tasks.
Combiner Functions
Many MapReduce jobs are limited by the bandwidth available on the cluster, so it pays to minimize the data transferred between map and reduce tasks.
Hadoop allows the user to specify a combiner function to be run on the map output, and the combiner function’s output forms the input to the reduce function.
Because the combiner function is an optimization, Hadoop does not provide a guarantee of how many times it will call it for a particular map output record, if at all.
In other words, calling the combiner function zero, one, or many times should produce the same output from the reducer.