
Replication and sharding are two common strategies used in distributed databases to improve performance, availability, and fault tolerance.
They each address different aspects of database scaling and data management. Let’s explore both concepts with examples:
Replication
Replication involves creating and maintaining multiple copies (replicas) of the same data on multiple servers or nodes within a distributed database system.
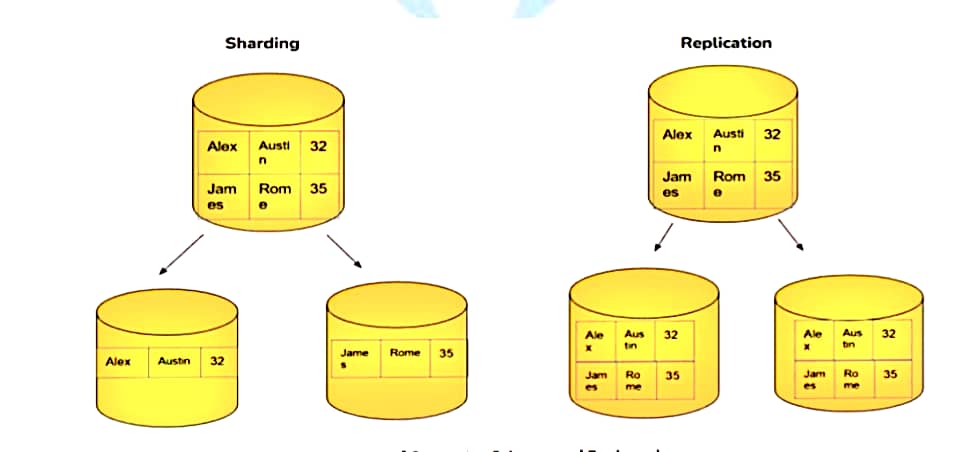
The purpose of replication is to improve data availability, fault tolerance, and read performance.
Key characteristics of replication:
✅High Availability: If one node fails, the data is still available on the other nodes, ensuring high availability.
✅Read Scalability: Multiple nodes can handle read operations simultaneously, distributing the read load.
✅Data Redundancy: Data redundancy is increased, as the same data is stored on multiple nodes.
✅Eventual Consistency: Replication often provides eventual consistency, meaning that eventually, all replicas will be updated, but there may be a slight delay
Sharding
Sharding, also known as horizontal partitioning, involves splitting a large database into smaller, more manageable parts called shards.
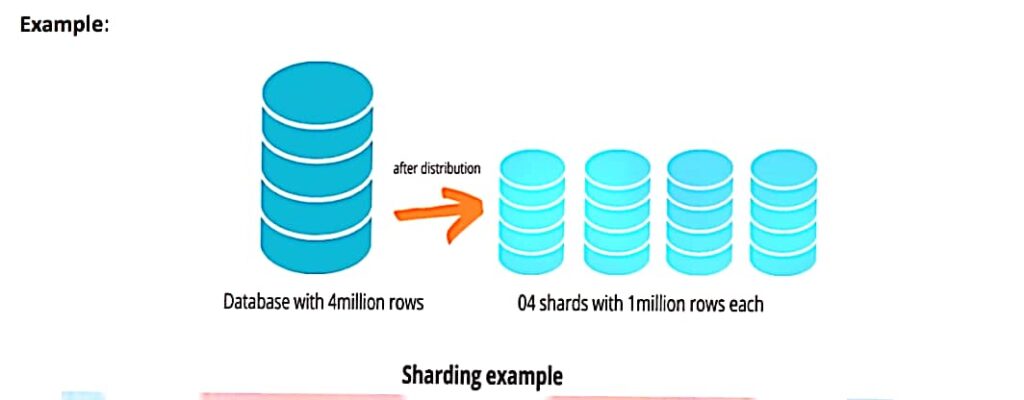
Each shard contains a subset of the data, and shards are distributed across multiple servers or nodes.
Sharding is primarily used to improve write scalability and distribute data evenly.
Key characteristics of sharding:
✅Write Scalability: Sharding significantly improves write scalability since data is distributed across multiple shards, reducing contention for resources.
✅Data Distribution: Data is distributed evenly across shards, preventing hotspots and ensuring efficient resource utilization.
✅Data Partitioning: Sharding requires a sharding key or strategy to determine which shard to store data on. Common sharding keys include user IDs, geographic locations, or date ranges.
✅Complexity: Sharding can introduce complexity into data management and query routing, as the application needs to be aware of the sharding strategy.
✅Data Isolation: Sharding can provide a degree of data isolation, ensuring that a failure in one shard does not affect other shards.
MapReduce on databases
MapReduce is a programming model and processing technique designed for distributed data processing tasks, particularly for processing and analyzing large datasets in parallel across a cluster of computers.
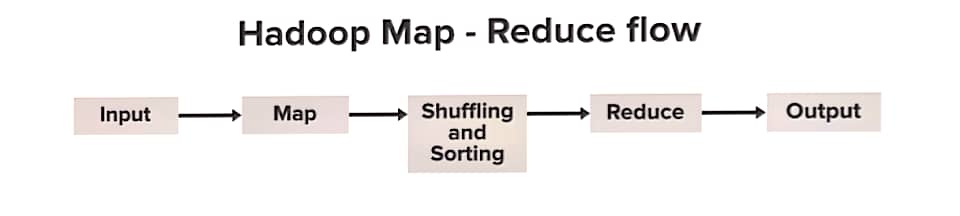
While it is often associated with Hadoop, MapReduce can also be applied to databases to perform distributed data processing tasks efficiently.
It’s especially useful when you need to perform operations that can be parallelized across a large dataset.
In the context of databases, MapReduce can be used to process and analyze large volumes of data stored in a distributed or parallel database system.
It divides a data processing task into two main stages: the Map stage and the Reduce stage.
Distribution models
Distribution models, in the context of data and computing, refer to strategies for distributing and managing data, workloads, or resources across multiple nodes, servers, or locations within a distributed system.
These models are essential for achieving scalability, fault tolerance, and efficient data processing in large-scale distributed environments.
Centralized Model: In a centralized model, all data and computing resources are concentrated in a single location or node.
This model is not inherently distributed and is suitable for small-scale applications.
Replication Model:Replication involves creating and maintaining multiple copies of data across different nodes. This model enhances data availability and fault tolerance
Partitioning (Sharding) Model: In this model, data is divided into partitions or shards, and each partition is stored on a separate node. It’s used to distribute data evenly and improve write scalability.
Distributed File System Model: Distributed file systems distribute files across multiple servers and provide a unified view of the file system to users and applications.
They often support replication for fault tolerance.
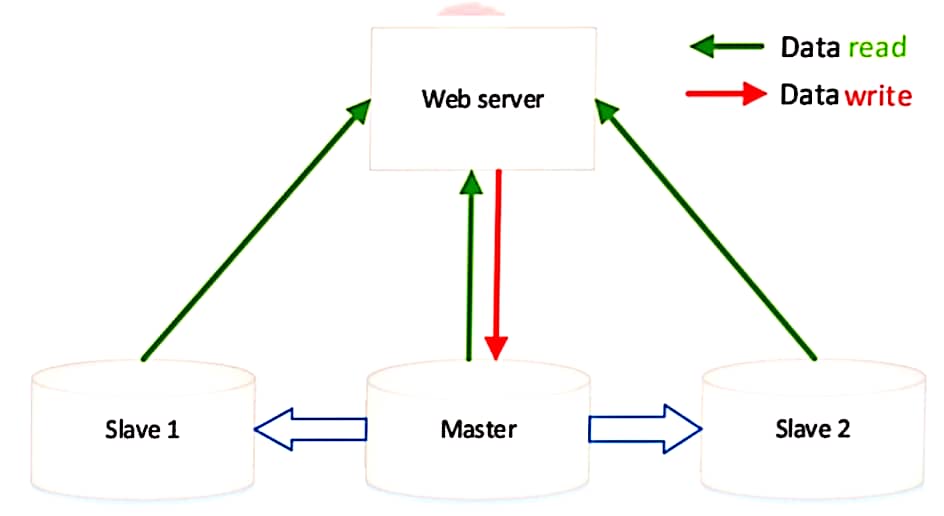
Master-Slave Model: In this model, there is a single master node responsible for coordinating and managing one or more slave nodes.
The master node distributes tasks to slaves and collects results.
Peer-to-Peer (P2P) Model: In a P2P model, nodes in the network communicate directly with each other, without a central server. Each node can act as both a client and a server.
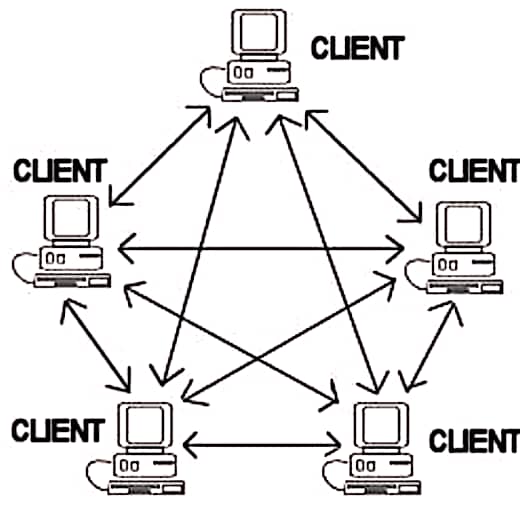
Federated Model: In a federated model, multiple autonomous systems or databases cooperate to provide a unified view or query access to their data.
Each system retains control over its data.
Data Center Model: Large organizations often maintain multiple data centers in different geographic locations. This model helps ensure high availability and disaster recovery.
Cloud Model: Cloud computing distributes resources and services across data centers owned and operated by cloud service providers.
OTHER COURSES : cloud computing
Leave a Reply